« Swifty 0.03 を公開しました | メイン | MySQL の高速化プチBK »
2007年09月19日
システムコールの最適化
今朝、会社で「最速のファイルコピー」についての話題が出ていました。そこで、ちょっと気になって、read(2) の呼出のオーバーヘッドがどの程度あるのか、ベンチマークをとってみました。
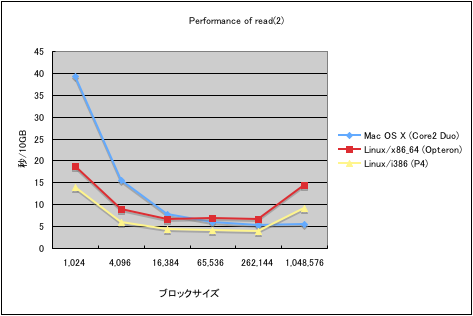
グラフは、それぞれの環境で、10MBのファイルを1,024回読み込むのにかかった時間を示しています。ファイルの内容は当然メインメモリにキャッシュされているので、実際は、カーネル内のバッファキャッシュからユーザープロセスのバッファへのメモリコピーの速度を測定していることになります。このグラフから、以下のような傾向を読み取ることができます。
- (言うまでもないことですが)システムコールのオーバーヘッドは大きい
- Mac OS X のシステムコールのオーバーヘッドは Linux の数倍注
- かといって、CPUの2次キャッシュから溢れるほどブロックサイズを大きくすると、速度が大幅に低下する
以上から、read(2) や write(2) 等の、カーネルとの間でメモリコピーを行うシステムコールを呼び出す際において、そのブロックサイズは2次キャッシュの50%を最大限にチューニングすべきひとつの目安とすべき注という風に言えるのかな、と思いました。
PS. ちなみに、linux のシステムコールのオーバーヘッドは、だいたい memcpy(1KB〜2KB) の所要時間と同等のようです。そういう風に覚えておくと、コーディング中に負荷をイメージしやすいかもしれません。
PS2. 測定に使用したソースコードと、結果の表を添付しておきます。あわせてごらんください。
#include <assert.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char** argv)
{
int fd, block_size, i, j;
static char buf[1048576] __attribute__((aligned(16)));
if (argc != 3 || sscanf(argv[2], "%d", &block_size) != 1) {
fprintf(stderr, "Usage: %s [file] [block_size]\n", argv[0]);
exit(99);
}
if ((fd = open(argv[1], O_RDONLY, 0644)) == -1) {
fprintf(stderr, "failed to open file: %s\n", argv[1]);
exit(1);
}
for (i = 0; i < 1024; i++) {
off_t off = lseek(fd, 0, SEEK_SET);
assert(off == 0);
for (j = 0; j < 10485760; j += block_size) {
int r = read(fd, buf, block_size);
assert(r == block_size);
}
}
return 0;
}
| ブロックサイズ | Mac OS X 10.4.10 Core 2 Duo@2GHz L1: 32KB, L2: 4MB |
Linux AMD64 (2.6.18) Opteron@1.4GHz L1: 64KB, L2: 1MB |
Linux i386 (2.6.17) Pentium 4@3.2GHz L1: 16KB, L2: 512KB |
| 1,024 | 39.19 | 18.82 | 13.842 |
| 4,096 | 15.52 | 8.918 | 5.833 |
| 16,384 | 7.7 | 6.664 | 4.446 |
| 65,536 | 5.914 | 6.781 | 4.028 |
| 262,144 | 5.317 | 6.659 | 3.939 |
| 1,048,576 | 5.578 | 14.327 | 9.077 |
投稿者 kazuho : 2007年09月19日 13:14 ![]()

トラックバック
このエントリーのトラックバックURL:
https://labs.cybozu.co.jp/cgi-bin/mt-admin/mt-tbp.cgi/1532