2009年02月06日
SSD (フラッシュメモリ) のベンチマークと選定基準
サーバ側での使用を目的とした SSD のベンチマークや選定基準については、これまでもいろいろ書いてきましたが、では、どのような点に着目して SSD を選定すべきかについて、少し触れておきたいと思います。というわけで、まずはベンチマークの紹介から。データベースのストレージとして使うことを念頭においた、16KB のランダムアクセステストです。
続きを読む "SSD (フラッシュメモリ) のベンチマークと選定基準"
投稿者 kazuho : 2009年02月06日 15:07
| コメント (2)
| トラックバック (0)
![]()

2008年11月27日
ウェブサービスの SSD 化について話してきました
本日 (11/27) 開催の Shibuya Perl Mongersテクニカルトーク#10 で、ウェブサービスの SSD 化について話しました。スライドを置いておきますので、開発しているウェブアプリケーションフレームワーク NanoA について話してきました とあわせてご覧いただければ幸いです。
末筆となりますが、Shibuya.pm の実行委員(?)の方々、ありがとうございました&おつかれさまです。 (まだ終わってないけど ^^;)
投稿者 kazuho : 2008年11月27日 20:40
| コメント (3)
| トラックバック (0)
![]()

2008年11月19日
ウェブアプリケーションのインストーラジェネレータ
CGI や PHP などの小さなウェブアプリケーションを配置(デプロイ)する際、アーカイブをインターネットからダウンロードして、適切な展開ツールで展開したのち、文字コードをあわせてディレクトリ丸ごとアップロード、というのは結構煩雑な手続きです。そこで、tar.gz から自己展開型の CGI を作成するインストーラジェネレータ tgz2cgi.pl を作ってみました。以下のような感じで使います。
% tgz2cgi.pl \
--title='MyApp インストーラー' \
--start='インストールを開始します' \
--end='インストールが終了しました。<a href="setup.cgi">次へ進む</a>' \
--delete --nph \
< myapp.tar.gz > nph-myapp-installer.cgi
このようにしてmyapp.tar.gz を展開するインストーラ nph-myapp-installer.cgi を作成することができます。上の例では、終了時のメッセージに「次へ」ボタンをつけて、展開されたパッケージの setup.cgi へユーザーを誘導しています。他のオプションは、以下のとおり。インストール終了後に自分自身を消去するモードもあります。特定のファイルが既に存在するかチェックして、見つかった場合はインストールを中止する --check-files オプションを使えば、誤って複数回実行してしまうこともありません。
$ ./tgz2cgi.pl --help Usage: ./tgz2cgi.pl [options] < package.tar.gz > installer.cgi Options: --title=title title when run as a CGI --start=msg start message --end=msg end message --nph create nph CGI --delete delete installer cgi on success --help show help
また、生成されるインストーラは、コマンドラインから直接実行することも可能です。この場合は、tar xzvf と同じ動作になります。生成されるインストーラの依存先は、perl (たぶん4以上), uudecode, tar, gzcat という、あまり時代を感じさせない、環境依存の少ない構成にしたつもりです。ぜひ、自己責任でお楽しみください。
15:41追記: uu(en|de)code は最近のディストリビューションでは標準インストールではないようなので、MIME::Base64 に変更しましたorz
投稿者 kazuho : 2008年11月19日 11:05
| トラックバック (0)
![]()

2008年09月12日
C++ テンプレートを使って MBCS と Unicode ちゃんぽんなコードを書く話
あちこちから寄せ集めたコードを組み合わせるようなプログラムを書いていると (Greasemetal のことですね)、プログラム内に MBCS 前提のコードと UTF16 前提のコードが混在することが往々にして発生します。
C++ の世界のみで完結できるのであれば、型テンプレートと関数の多重定義を使って総称的なコードを簡単に書けるのですが、実際は、MBCS 版と UTF16 版で関数の名称が異なる C API を呼び出す必要が出てきたりします。具体的には、RegQueryValueExA と RegQueryValueExW を (あるいは fgets と fgetws を)、自動的に呼び分ける総称的なコードが書きたい、といったケースになります。
で、うーん、と思った結果、以下のようなコードを書いてみました。
続きを読む "C++ テンプレートを使って MBCS と Unicode ちゃんぽんなコードを書く話"
投稿者 kazuho : 2008年09月12日 10:22
| トラックバック (0)
![]()

2008年07月25日
最適化された最適化手法について
昨日ソフリットを会場に (壇上さん++) 開催された CodeRepos Conference #1 に参加してきました。お題は「自重しないで coderepos に貴様がいれているプロダクトについて語れ!」ということだったので、そのあたりを例に挙げながら、自分は最適化手法について (空気を読まずに) 話しました。
どちらかと言うとサーバの最適化設計を中心にした話です。いろいろ荒削りですが、そうだね、とか、そこは違うよ、とか指摘いただければ幸いです。発表の動画がニコニコ動画にアップロードされているので (coji さんありがとうございます) よろしければあわせてご覧ください。
投稿者 kazuho : 2008年07月25日 09:35
| トラックバック (1)
![]()

2008年06月27日
C++ で自動型変換
C++ の拡張ライブラリである boost には、lexical_cast というライブラリがあって、iostream への入出力ができる型ならなんでも文字列化 (その逆も) できるので、とても便利です。でも、lexical_cast は、int → long のような変換の場合にも iostream を使った変換をしてしまうので、汎用のリフレクションコードを書こうとすると、そのままでは使いにくいです (オーバーヘッドが大きすぎる)。というわけで、変換前後の型に応じて、static_cast と lexical_cast を自動的に切り替えるようなキャスト関数を作ってみました。こんな感じで使います。
// calls lexical_cast<int>(123)
int i = intelligent_cast<int>("123");
// calls static_cast<long>(123)
long l = intelligent_cast<int>(123);
// calls std::string(const char*)
std::string s = intelligent_cast<std::string>("abc");
これで、不用意に数値型間や std::string → std::string のような変換 (コピー) が必要になる場合でも、速度の低下を心配する必要がなくなりました。
ライブラリのコードは以下のような感じ。boost におんぶにだっこなので簡単です (std::string については、実用上の観点から専用コードを追加しています) 。最新版は CodeRepos (/lang/cplusplus/reflection) においてあるので、バグ等ありましたら、指摘もしくは修正いただければ幸いです。
投稿者 kazuho : 2008年06月27日 17:22
| トラックバック (0)
![]()

2008年06月25日
なんとなくリフレクション in C++
C++ はとてもいい言語なのですが、リフレクションがありません。昨夜、1年ぶりくらいに C++ でリフレクションしたい熱に感染したのですが、ちょっとググった範囲では良いものが見つからなかったので、作ってみました (単に作りたかっただけという説も)。こんな感じで使います。
#include "reflection.hpp"
struct Foo {
int i;
std::string s;
};
// リフレクション情報を定義
namespace reflection {
template <> struct def<Foo> : public def_base<Foo> {
def() {
REFLECTION(i);
REFLECTION(s);
}
};
};
// リフレクションを通してデータを読み込み
// 変数が見つからない場合は reflection::name_not_found_error が、
// キャストできない場合は std::bad_cast 例外が送出されます
int t = reflection::get<int>(f, "i");
cout << "i=" << t << endl;
// リフレクションを通してデータを書き込み
reflection::set(f, "s", string("hello world"));
// リフレクション情報を iterate して表示
for (reflection::def<Foo>::const_iterator i =
reflection::def<Foo>::map.begin();
i != reflection::def<Foo>::map.end();
++i)
cout << i->first << " = "
<< i->second->get<std::string>(f) <<endl;
このリフレクションライブラリの特徴は、以下のようなものになります。
投稿者 kazuho : 2008年06月25日 08:34
| トラックバック (0)
![]()

2008年06月12日
MySQL (InnoDB) に直接アクセスしてタイムライン処理を高速化する話
フレンド・タイムライン処理の原理と実践 の続きです。
先のエントリでは、プルモデルの速度が当初予測していたよりも遅かった (というより SQL レイヤでのオーバーヘッドが大きそうだった) ので、MySQL Internals メーリングリストで質問したりしながら、C++ で直接 InnoDB にアクセスするようなコードを書いてみました。
| タイムライン/秒 | |
|---|---|
| SQL | 56.7 |
| ストアドプロシージャ | 136 |
| C++ での直接アクセス |
そしたら、10倍以上高速に! ベンチマークを perl ベースのものから mysqlslap に変えたのですが、プッシュモデルの 2/3 の速度が出ています。これなら、データサイズが約 1/10 になることを考えると、メモリの代わりに CPU に投資するほうが良い、という判断も非常に現実味を帯びてきます。また、最近のクアッドコアな CPU を使えば 10,000 タイムライン/秒クラスも夢じゃないでしょうから、memcached による支援の必要もないのかもしれません。
続きを読む "MySQL (InnoDB) に直接アクセスしてタイムライン処理を高速化する話"
投稿者 kazuho : 2008年06月12日 17:12
| コメント (1)
| トラックバック (0)
![]()

2008年06月09日
フレンド・タイムライン処理の原理と実践
MySQL (InnoDB) に直接アクセスしてタイムライン処理を高速化する話に続きます。
Twitter が注目されるようになって久しい今日この頃ですが、友人の投稿を時系列に並べて表示する、というのは、Twitter に限らず Mixi の「マイミクシィ最新日記」やはてなブックマークの「お気に入り」等、ソーシャルなウェブサービスにおいては一般的な手法です。ですが、この処理 (以下「フレンド・タイムライン」と呼ぶ) は、一見簡単そうに見えて、実装には様々な困難が伴います。本記事では、「フレンド・タイムライン」を実現する、プッシュ型とプル型の二種類の手法について、その原理的な特徴と問題、および実践的なテクニックについて説明したいと思います。
なお、以下では基本的に SQL を用いて話を進めて行きますが、原理的な部分は、どのようなストレージを使おうと、あるいはスケールアウトしようがしまいが、変わらないと思います。
1. プッシュ型
投稿者 kazuho : 2008年06月09日 14:06
| コメント (8)
| トラックバック (6)
![]()

MySQL のクエリ最適化における、もうひとつの検証方法
EXPLAIN を使用して MySQL の SQL を最適化するというのは、良く知られた手法だと思います。しかし、EXPLAIN の返す結果が、かならずしもアテになるわけではありません。たとえば、以下のような EXPLAIN を見て、このクエリが最適かどうか、判断ができるでしょうか。私には分かりません。
続きを読む "MySQL のクエリ最適化における、もうひとつの検証方法"
投稿者 kazuho : 2008年06月09日 11:38
| トラックバック (0)
![]()

2008年05月01日
データベースの差分バックアップとウェブサービスのお引っ越し
現在、Pathtraq のサーバを、オフィス内のサーバルームに設置されたマシンからデータセンタ内の新サーバへ移行する作業を行っています。その際に問題となるのは、ダウンタイムを最小にしつつ、100GB 弱ある MySQL のデータをいかに移動させるか、という点になります。答えは言うまでもなく差分転送なのですが、rsync は双方向の接続が必須だったり、差分情報をキャッシュすることができなかったり、いろいろ融通が効かなそうです。だんだん調べるのも面倒になってきたので、自分のニーズに見合う、データベースファイル用の差分バックアッププログラムを書いてみました。
/lang/c/blockdiff - CodeRepos::Share - Trac差分ファイルとハッシュ値の情報が別ファイルになっていたり、ファイルデスクリプタを積極的に使ったりと、柔軟な運用が可能な設計になっています (getopt とかファイル構造考えたりとかが面倒だったとも言います)。使い方は、以下のような感じ。
続きを読む "データベースの差分バックアップとウェブサービスのお引っ越し"
投稿者 kazuho : 2008年05月01日 15:56
| トラックバック (1)
![]()

2008年04月18日
C++ テンプレートを使って高速な高機能サーバを書く方法
「C++ のメンバ関数ポインタって何のためにあるの」という質問を耳にすることがあります。実際は、たとえばステートマシンを書くのに便利なのですが、ちょうどサイボウズ・ラボの C++ 熱が盛り上がっていることもあり、昔の作ったサーバフレームワークを再実装してみました。ちなみにもともとは、1990年代に東京大学駒場キャンパスで使われていた friends というサービスのバックエンドだった、finger プロキシ用に書いたコードです。ソースコードは /lang/cplusplus/friends_framework - CodeRepos::Share - Trac においてあります。特徴は以下のとおり:
- シングルスレッド、select(2) ベースによる実装
- C++ テンプレートとメンバ関数ポインタによるステートマシン化
- タイムアウト処理の容易な組み込み
実際の処理をどのように書くかは、test/proxy.cpp をご覧いただければいいと思います。これは TCP の L4 Proxy を実装したものですが、関数ポインタとフラグの切り替えによって、転送処理とタイムアウト処理を実装しています。
続きを読む "C++ テンプレートを使って高速な高機能サーバを書く方法"
投稿者 kazuho : 2008年04月18日 16:39
| トラックバック (0)
![]()

2008年02月22日
Range Coder の終了処理
CodeZine:高速な算術圧縮を実現する「Range Coder」(算術圧縮, データ圧縮, Range Coder)等を見ていると、多くの Range Coder の実装では、終了処理において冗長な出力をしているようです。
私の理解と記憶が正しければ、予測の上限値と下限値が異なる最初のビットまで出力すれば、残りのビットの出力は不要なはずです。Range Coder が一般化する以前の、ビット単位の操作を行っていた Jones 符号化器はそのような実装がされていたように思うのですが、Range Coder で速度を稼ぎ始めた時に、この点が見過ごされるようになったのでしょうか。
もちろんデータサイズが大きい際は、この点に起因する数バイトの無駄は問題はならないのですが、小さなデータを多数、静的テーブルを用いて圧縮するような場合は、無視できない影響が発生します。奥は Range Coder をちゃんと見たのは昨日が初めてなので、理解が間違っているかもしれませんが、備忘録をかねてブログエントリに起こしておきたいと思います。
21:56追記: CodeZine 上にある岡野原さんのコードは BSD ライセンスらしいので、奥の改変版を /lang/cplusplus/range_coder/range_coder.hpp - CodeRepos::Share - Trac にコミットしました。よろしければご覧ください。
投稿者 kazuho : 2008年02月22日 20:55
| コメント (1)
| トラックバック (0)
![]()

2008年01月30日
setlock を使って cron をぶんまわす方法
事前計算や DB 再構築を手軽に実行するのに cron は便利ですが、タスクのまわし過ぎによるサービスのパフォーマンス低下や実行順序の制御を別途行う必要があります。自分は、そのためのツールとして、daemontools の setlock コマンドがお気に入りです。setlock は、flock を用いて、タスクの待機や実行中止を制御することのできる、とても小回りのきくプログラムです。
1-59/* * * * * /usr/local/bin/setlock -nx /tmp/precompute.lock /usr/local/bin/setlock /tmp/allcron.lock precompute --mode=minutely 0 1-23/* * * * /usr/local/bin/setlock /tmp/precompute.lock /usr/local/bin/setlock /tmp/allcron.lock precompute --mode=hourly 0 0 * * * /usr/local/bin/setlock /tmp/precompute.lock /usr/local/bin/setlock /tmp/allcron.lock precompute --mode=daily && /usr/local/bin/setlock /tmp/allcron.lock rebuild_db
たとえば、上の cron は、以下のようなことを実現しています。
- 毎分1回、前回の処理が完了している場合のみ、毎分行うべき事前計算処理 (precompute --mode=minutely) を行う
- 毎時1回、毎時必ず行うべき事前計算処理 (precompute --mode=hourly) を行う
- 毎日1回、毎日必ず行うべき事前計算処理 (precompute --mode=daily) を行う
- 毎日1回、日次の事前計算処理の完了後に、データベースの再構築 (rebuild_db) を行う
- これらのタスクは、すべて順列化されて実行され、同時に複数が動作することはない
最近はマルチコア環境が一般化しつつあるので、処理が CPU インテンシブな場合は、このようにして特定のCPUコアをバックグラウンドタスクに張り付けるというアプローチも可能です。また、HDD やメモリのバンド幅が問題になる場合は、それぞれのタスク内で sleep させることで、負荷の調節が可能です。DBIx::Replicate には、そのような仕組み (load アトリビュート) が入っています。
投稿者 kazuho : 2008年01月30日 11:08
| トラックバック (0)
![]()

2008年01月29日
データベースをコピーするモジュール DBIx::Replicate
データベースをオンデマンドでコピーするモジュール DBIx::Replicate を書いて、CodeRepos にアップロードしました。こんな感じで使います。
use DBIx::Replicate qw/dbix_replicate/;
# 20才以下の人だけを young_table にコピー (1000行毎, 最大負荷 0.5)
dbix_replicate({
src_conn => $dbh,
src_table => 'all_people',
dst_conn => $dbh,
dest_table => 'young_people',
primary_keys => [ qw/id/ ],
columns => [ qw/id name age/ ],
block => 1000,
load => 0.5,
extra_cond => 'age<20',
});
# zipcode 毎にクエリを分割してテーブル全体をコピー
dbix_replicate({
src_conn => $src_dbh,
src_table => 'tbl',
dest_conn => $dest_dbh,
dest_table => 'tbl',
copy_by => [ qw/zipcode/ ],
});
1回のクエリで転送する量を行数あるいはカラムの値で制限することができるので、テーブルをダンプしての転送やレプリケーションよりも柔軟な運用が可能かと思います。もちろん、コピーできるテーブルの大きさに制限もありません。たとえば、以下のような場合に便利かもしれません。
- 異なるRDBMS間でデータをコピーしたい
- インクリメンタルコピーでいいから、転送中に発生するロックを最小限にしたい
- 絞り込みを行いつつデータをコピーしたい
- InnoDB を使っているが mysqldump --single-transaction | ssh mysql 等だとメモリ負荷が大きい
現状の問題としては、以下のようなものがあります。
- トランザクションを使っているので MyISAM のコピーには使えない
- MySQL は delete の条件節内の (min_a,min_b)<=(a,b) and (a,b)<(max_a,min_b) をrangeクエリに最適化してくれないので、複合プライマリキーをコピーする場合には、上の使用例の下のタイプである copy_by を使う必要がある
といったあたりです。もともと手元で動かしていたものを、ユニットテストを書きたくなったがために分割してモジュール化したので ad-hoc なコードですがご容赦いただければ。誰か OO な設計にリファクターして、いろんなコピー戦略を実装できるようにしてくれないかなぁ。
投稿者 kazuho : 2008年01月29日 16:03
| トラックバック (1)
![]()

2008年01月04日
ウェブアプリケーションにおけるHDDの正しい使い方
データベース等のソフトウェアは一般に、停電やOSのクラッシュ時にデータが破壊されないよう、HDD へデータ保存が完了したか確認しながら処理を行うようになっています。その目的を果たすためにどのような API が OS によって提供されているか、少し勉強し直すことにしました。
下表のうち、赤い部分がデータの永続性が保証されない危険な手法、青い部分が安全な手法です。したがって、各行において出来るだけ左側の (高速側の) 、そして言うまでもなく青い色の同期手法を使っていることが望ましいということになります。
| OS | openモード | HDD または RAID 内の書込先 | |
|---|---|---|---|
| キャッシュ (高速) | プラッター (低速) | ||
| Linux注1 | 同期 | open(O_SYNC) | fdatasync |
| 非同期 | N/A | fdatasync | |
| Linux+UPS注2 Linux+RAID注3 |
同期 | open(O_SYNC) | N/A |
| 非同期 | fdatasync | N/A | |
| Windows | 同期 | CreateFile(FILE_FLAG_WRITE_THROUGH) | FlushFileBuffers |
| 非同期 | N/A | FlushFileBuffers | |
| Windows+UPS | 同期 | CreateFile(FILE_FLAG_WRITE_THROUGH) | FlushFileBuffers |
| 非同期 | N/A | FlushFileBuffers | Windows+RAID注3 | 同期 | CreateFile(FILE_FLAG_WRITE_THROUGH) | N/A |
| 非同期 | FlushFileBuffers | N/A | |
| Mac OS X | 同期 | N/A | |
| 非同期 | fsync | fcntl(F_FULLFSYNC) | |
| Mac OS X+UPS | 同期 | N/A | |
| 非同期 | fsync | fcntl(F_FULLFSYNC) | |
| Mac OS X+RAID注3 | 同期 | N/A | |
| 非同期 | fsync または fcntl(F_FULLFSYNC) | N/A | |
| Solaris | 同期 | open(O_SYNC) | ioctl(DKIOFLUSHWRITECACHE) |
| 非同期 | fdatasync | ioctl(DKIOFLUSHWRITECACHE) | |
| Solaris+UPS | 同期 | open(O_SYNC) | ioctl(DKIOFLUSHWRITECACHE) |
| 非同期 | fdatasync | ioctl(DKIOFLUSHWRITECACHE) | |
| Solaris+RAID注3 | 同期 | open(O_SYNC) | N/A |
| 非同期 | fdatasync または ioctl(DKIOFLUSHWRITECACHE) | N/A | |
実際に表を起こしてみて、以下のようなことがわかりました。
続きを読む "ウェブアプリケーションにおけるHDDの正しい使い方"
投稿者 kazuho : 2008年01月04日 16:13
| コメント (4)
| トラックバック (0)
![]()

2007年12月28日
ディスクが1回転する間に複数回 fdatasync する方法について
RDBMS のトランザクション速度は HDD の回転数に律速されるというのは、おそらく常識だと思います。たとえば MySQL のドキュメントには、以下のような記述を見ることができます。
もしディスクが OS を 「欺かなければ」、ディスクの回転速度は一般的に最大167 回転/秒で、コミット数も1秒につき167th に制限されます。
MySQL AB :: MySQL 5.1 リファレンスマニュアル :: 13.5.11 InnoDB パフォーマンス チューニング ヒント
でもその限界って、ディスクの異なる角度の位置に複数のブロックを配置して、1周する間に順次 write + fdatasync していけば超えられるんじゃないか、ということで実証コードを書いてみました。
続きを読む "ディスクが1回転する間に複数回 fdatasync する方法について"
投稿者 kazuho : 2007年12月28日 13:27
| トラックバック (0)
![]()

2007年10月11日
MySQL のウォームアップ (InnoDB編)
サーバの起動直後はデータがメモリ上にないためデータベースの応答速度が遅い、というのは良く知られた話かと思います。MySQL の場合、使っているエンジンが MyISAM であれば、各データファイルをあらかじめ cat ... > /dev/null するなりしてバッファキャッシュに載せておけばいいのですが、InnoDB は独自のキャッシュを持っているのでそういうわけにもいかないように思います。
具体的には、パフォーマンスを最大限発揮するためには OS のキャッシュにではなく、InnoDB のバッファプールにデータをロードすべきであるという点。それに、たとえ OS のキャッシュを利用するので良しとするケースでも、サーバの実メモリの過半をバッファプールに使用しているような場合だと、バッファプールを確保するために OS のキャッシュにロードしたデータが破棄されるケースが出てくるという点が、問題となるのではないでしょうか。
じゃあどうすんべ、とお風呂の中で考えた結果、以下の案にたどり着きました。たぶんこの手順で問題ないと思うのですが、間違いがあればツッコミを入れていただければ幸いです。
続きを読む "MySQL のウォームアップ (InnoDB編)"
投稿者 kazuho : 2007年10月11日 22:44
| トラックバック (1)
![]()

2007年09月28日
DBI::Printf - A Yet Another Prepared Statement
Java や C++ のような関数のオーバーロードができる言語では、プリペアードステートメントのプレースホルダが型をもつ必要はありません。しかし、Perl のように数値型と文字列型の区別がない言語で最善を期そうとすると、変数をバインドするタイミングで型を意識してコードを書かなければならず面倒です。 (参考: MySQL の高速化プチBK)
だったら、printf のように、プリペアードステートメントのプレースホルダで型を指定できればいいのに、と、もともとは Twitter でつぶやいたネタなのですが、SQLステートメントをキーとしてキャッシュにデータを保存したいといった事情もあって、実際に作ってしまいました。
続きを読む "DBI::Printf - A Yet Another Prepared Statement"
投稿者 kazuho : 2007年09月28日 10:10
| コメント (2)
| トラックバック (2)
![]()

2007年09月27日
ウェブサービスのためのMutex - KeyedMutex
昨日、以下のように書いたのですが、両者のうち2番目のアプローチを実現する Perl モジュール KeyedMutex を作成しました。
サーバにおける Thundering Herd 問題は良く知られていると思いますが、類似の現象はキャッシュシステムでも発生することがあります。
(中略)
対策としては、以下の2種類の手段があります。これらの手法には、それぞれメリットとデメリットがあり、アプリケーションによって最適な方法は異なります。
- バックエンドへの同一リクエストを束ねるような仕組みを実装する
- エクスパイヤ以前の残存時間が一定以下となった段階で、キャッシュエントリのアップデートを開始する
Kazuho@Cybozu Labs: キャッシュシステムの Thundering Herd 問題
KeyedMutex は、クライアントが指定した鍵毎に排他処理を行うサーバ・クライアント型のシステムです。キャッシュへのデータ保存と連動させることで、データベースへの余分な問い合わせを抑制し、動作効率を高めることができます。以下のような感じで使用します。
続きを読む "ウェブサービスのためのMutex - KeyedMutex"
投稿者 kazuho : 2007年09月27日 15:46
| トラックバック (0)
![]()

2007年09月26日
キャッシュシステムの Thundering Herd 問題
サーバにおける Thundering Herd 問題注1は良く知られていると思いますが、類似の現象はキャッシュシステムでも発生することがあります注2。
通常、キャッシュに格納されるデータは、それぞれ単一の生存時間をもっています。問題は、頻繁にアクセスされるキャッシュデータがエクスパイアした際に発生します。データがエクスパイヤした瞬間から、並行に走る複数のアプリケーションロジックがミスヒットを検知し、いずれかのプロセスがキャッシュデータを格納するまでの間、同一のリクエストが多数、バックエンドに飛んでしまうのです。
対策としては、以下の2種類の手段があります。
続きを読む "キャッシュシステムの Thundering Herd 問題"
投稿者 kazuho : 2007年09月26日 10:11
| コメント (2)
| トラックバック (0)
![]()

2007年09月20日
MySQL の高速化プチBK
鴨志田さんに教えていただいたのですが、MySQL のクエリは数値をクォートしない方が高速になるらしいです。たとえば以下の例では、160万件の整数から4の倍数を数えていますが、数値をクォートしないほうが約50%も高速になっています。
投稿者 kazuho : 2007年09月20日 12:06
| コメント (1)
| トラックバック (2)
![]()

2007年09月19日
システムコールの最適化
今朝、会社で「最速のファイルコピー」についての話題が出ていました。そこで、ちょっと気になって、read(2) の呼出のオーバーヘッドがどの程度あるのか、ベンチマークをとってみました。
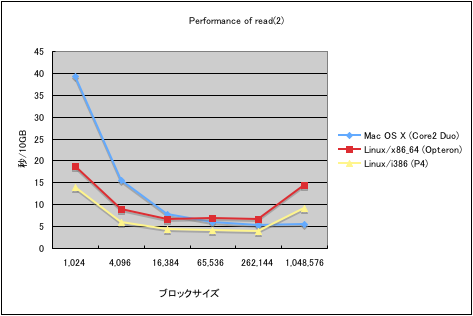
グラフは、それぞれの環境で、10MBのファイルを1,024回読み込むのにかかった時間を示しています。ファイルの内容は当然メインメモリにキャッシュされているので、実際は、カーネル内のバッファキャッシュからユーザープロセスのバッファへのメモリコピーの速度を測定していることになります。このグラフから、以下のような傾向を読み取ることができます。
投稿者 kazuho : 2007年09月19日 13:14
| トラックバック (0)
![]()

2007年09月05日
サーバシグニチャは隠さないのが当たり前
ウェブサーバ(Apache)で、404などのエラーページを表示したとき、ヘッダやページの下にApacheやOSのバージョンが表示されます。こういったサーバ情報をわざわざ表示する必要はありません。
ウノウラボ Unoh Labs: 5分でできるウェブサーバのセキュリティ向上施策
私も何年も前からセミナーではサーバ、モジュールバージョンは隠すようにと言っています。何故こんな事で賛否両論になるのか全く理解できません。
yohgaki's blog - サーバシグニチャは隠すのが当たり前
Server: ヘッダを隠すメリットについての議論はあるようですが、Server: ヘッダを表示すべき理由についての解説がないようなので、知っていることを書いておきたいと思います。
投稿者 kazuho : 2007年09月05日 10:27
| トラックバック (1)
![]()

2007年05月10日
Cache::Adaptive の使い方
昨日のエントリが好評のようだったので、いろいろ問題を修正したバージョンを CPAN にアップロードしました (Cache-Adaptive-0.02 - search.cpan.org) 。ついでに、開発中のウェブサービスに仕込んで、トップページでベンチマークを取ってみました。こんな感じです。
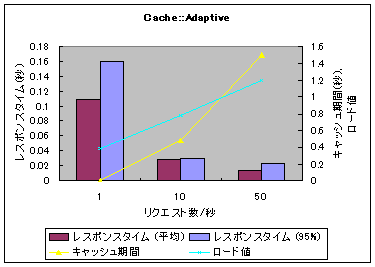
投稿者 kazuho : 2007年05月10日 17:26
| トラックバック (0)
![]()

2007年04月16日
Gungho をインライン化してみた
ちょっとクローラーが必要になったのですが、POE の勉強は面倒なので Gungho を使って作ることにしました。開発が始まったばかりっぽいけど、使いやすそうだし期待大ということで。で、コードを読んでいて思ったのは、provider (URL をフィードするモジュール) と handler (ダウンロードしたコンテンツを処理するモジュール) は再利用されない (=各アプリケーション専用の処理になる) 場合も多いんじゃないかということ。だったらいちいちパッケージ定義して設定値渡しとか面倒だよねというか、ぶっちゃけ自分がクロージャで書きたいと思ったので、ラッパーを書いてみました。こんな感じで使えます。
投稿者 kazuho : 2007年04月16日 10:35
| コメント (2)
| トラックバック (0)
![]()

2007年02月23日
Comet の正しい使い方
今日会社の勉強会で Comet について話す機会がありました。
Comet については、普及するかどうかという以前に、どう使えばいいのか、正しく使った場合に何をどこまでできるのか、という理解が共有されていないように思います。なので、(あくまで私見ですが) 使用したスライドの一部を公開したいと思います。よろしければごらんください。また、問題や改善すべき点があれば、教えていただければ幸いです。

投稿者 kazuho : 2007年02月23日 15:33
| コメント (2)
| トラックバック (5)
![]()

2006年11月29日
独自ドメインにおける DNS の設定
レンタルサーバを使って独自ドメインのウェブサイトを立ち上げる際、悩むのが DNS の設定です。王道としては、レンタルしたサーバでプライマリサーバを立ち上げセカンダリはどこかのサービスのものを使用するというパターンと、まるごと Dynamic DNS のようなサービスに頼るというパターンがあると思います。しかし、他の選択肢も存在します。DNS は学習曲線が長そうなので近づかないようにしてきたのですが、今回、mylingual.net というドメインを取得したので、いろいろ試してみることにしました。
1. DNS サーバは2つ以上必要なのか
独自ドメインで運用するサーバが一台のみなのであれば、その1台でウェブサーバと DNS サーバを兼用させ、セカンダリ DNS を使用しないという手もあります。一般に DNS サーバを複数台用意すべきとされる理由は、1台の DNS サーバが落ちた際にドメイン全体が使用不可能にならないようにするためです。しかし、ドメイン唯一のサーバであるウェブサーバと同時に DNS サーバが落ちるのであれば、あまり問題がないはずです注1。
全てのドメインで可能なわけではありません注2が、.com や .net といった gTLD ではプライマリ DNS とセカンダリ DNS に同一の IP アドレスを登録することにより、このような運用が可能です。
2. グルーレコードの積極的な活用
投稿者 kazuho : 2006年11月29日 10:41
| トラックバック (0)
![]()

2006年06月29日
DNS ラウンドロビンと高可用性 (High Availability)
ウノウラボ Unoh Labs - ベンチャー流サーバ構築のススメ(ネットワーク編) について。
おもしろく読ませていただきました。また、監視系を導入せずに自律的に動作させようという発想も大好きです。
でも、
続きを読む "DNS ラウンドロビンと高可用性 (High Availability)"
投稿者 kazuho : 2006年06月29日 10:35
| コメント (6)
| トラックバック (2)
![]()

2006年06月01日
[メモ] coLinux
1) slirp について
colinux 0.6.3 の slirp は不安定。
ノート PC で LAN 接続を切り替えながら使いたい、といった場合は、http://www.henrynestler.com/colinux/testing/ から最新版を取ってくれば良い。
2) ディスク容量の節約
投稿者 kazuho : 2006年06月01日 16:03
| トラックバック (0)
![]()

2006年03月15日
今日から始める Server-side JavaScript
サーバサイドのプログラムを JavaScript で書くことができれば、入力チェックルーチン等をクライアント側と統一できるのになぁ、でも、 Server-Side JavaScript の実行環境って、なかなかいいのがないんだよなぁ、と思っていました。
オオボケです>自分
続きを読む "今日から始める Server-side JavaScript"
投稿者 kazuho : 2006年03月15日 16:29
| トラックバック (1)
![]()

2006年02月14日
cygwin + mod_perl
cygwin に apache/2.0 + mod_perl をインストールしようとして苦労しました。備忘録を兼ねて、ブログに手順を書いておきたいと思います。
投稿者 kazuho : 2006年02月14日 14:21
| トラックバック (0)
![]()

2006年02月08日
キャッシュの上手な使い方
キャッシュといっても、ウェブブラウザやウェブプロキシのキャッシュのことです。
・Internet Explorer のキャッシュの動作
投稿者 kazuho : 2006年02月08日 01:00
| コメント (2)
| トラックバック (3)
![]()

2006年01月04日
URL と Base64
URL にバイナリデータを埋め込んで渡すことが、ままあります。私のケース注1では、バイナリデータが結構大きかったので hex encode は避けたいところ。 base64 エンコードしようと思ったのですが、 path や query に + や / といった文字は入れたくありません。
じゃあ、みんなどうしているのかな、と思って、聞いたり調べたりしたところ、いろいろな変換方式があるようです。
投稿者 kazuho : 2006年01月04日 15:13
| コメント (2)
| トラックバック (2)
![]()

2005年09月22日
prototype.js のイベント順序
prototype.js (1.3.1) を使用していて、奇妙な現象にぶつかったので、メモをかねてブログ。
prototype.js を非同期モード (asynchronous:true) で実行している場合、 onComplete の後に onLoading が呼ばれることがある。
原因は、prototype.js のこのコード:
if (this.options.asynchronous) {onLoading を自前でスケジュールしている点。
this.transport.onreadystatechange = this.onStateChange.bind(this);
setTimeout((function() {this.respondToReadyState(1)}).bind(this), 10);
}
たぶん、なんらかの理由があってそうなっているんだろうけど (どうして?) 、イヤな仕様ですね。
とりあえず、 onComplete ハンドラで onLoading ハンドラをリセットすることで、問題に対処しました。
投稿者 kazuho : 2005年09月22日 11:47
| コメント (5)
| トラックバック (0)
![]()
